In day to day biostatistics and scientific data analysis, researchers deal with increasingly large and complex datasets. From clinical trials to epidemiological surveys and pharmaceutical R&D, data used is often imbalanced,redundant, or computationally heavy. To overcome these challenges, researchers rely on sampling techniques.
Sampling is a foundational concept in biostatistics biostatistics and research methodology. Rather than measuring or observing an entire population (which can be costly or infeasible), researchers often select a sample of a subset of the population that represents the population of interest. The art and science lies in selecting that sample well, so that conclusions drawn can be generalized back to the population with confidence.
Biostat Prime, a powerful statistical and graphing software, simplifies this process with built-in tools for up-sampling and down-sampling. These techniques help researchers optimize datasets for accuracy, efficiency, and fairness in analysis.
Fundamental Concepts in Sampling
- Population (or Universe): The complete set of subjects, units, or observations of interest. Example: all school children in a city or all cases of a disease in a country.
- Sample: A subset of the population selected for study that mirrors the characteristics of the broader population.
- Sampling: The process or method by which a sample is drawn from the population. Sampling requires the definition of sampling units (the smallest units that can be selected) and a strategy for selection.
A good sampling strategy ensures that your sample is representative, unbiased, and suitable for statistical inference.
What is Sampling in Biostatistics ?
Sampling refers to the process of selecting a portion of data points from a larger dataset to conduct analysis. Instead of working with the full dataset, which may be too large or researchers create a representative sample that maintains and explains the overall structure of the population.
Why Sampling Matters in Biostat Prime
- Ensures balanced groups for fair comparison.
- Reduces processing time for large-scale datasets.
- Prevents bias by handling imbalanced groups.
- Improves reliability of statistical tests and models.
- Makes scientific graphing and visualization clearer.
Example: In a clinical drug trial, if most participants are adults aged 40–60 and very few are under 30, the dataset becomes imbalanced. Sampling helps correct this imbalance for more representative conclusions.
Advantages of Using Sampling
- Cost-Effective and Resource-Efficient: Studying an entire population is often impractical. Sampling minimizes expenses, saves time, and reduces logistical challenges.
- Quicker Data Collection and Analysis: Working with smaller datasets allows for faster data gathering, cleaning, and analysis.
- Improved Accuracy: With fewer samples to handle, researchers can maintain better quality control, take more precise measurements, and closely monitor the sampling process.
- Enhanced Participant Interaction: Engaging with a smaller number of respondents makes it easier to build trust, prevent fatigue, and improve response rates.
Challenges Encountered in Sampling
- Possibility of Bias:If the sampling technique is poorly designed, the sample may not accurately reflect the population.
- Challenges in Achieving True Representation: In large or diverse populations, ensuring every subgroup is proportionally represented can be difficult.
- Requirement for Expertise: Effective sampling design and execution demand sound statistical knowledge and careful planning.
- Limited Applicability: When the population is too small or highly diverse, sampling may not provide a valid representation.
To overcome these limitations, careful attention should be given to sampling design, methodology, and validation procedures.
Steps to Perform Sampling in Biostat Prime
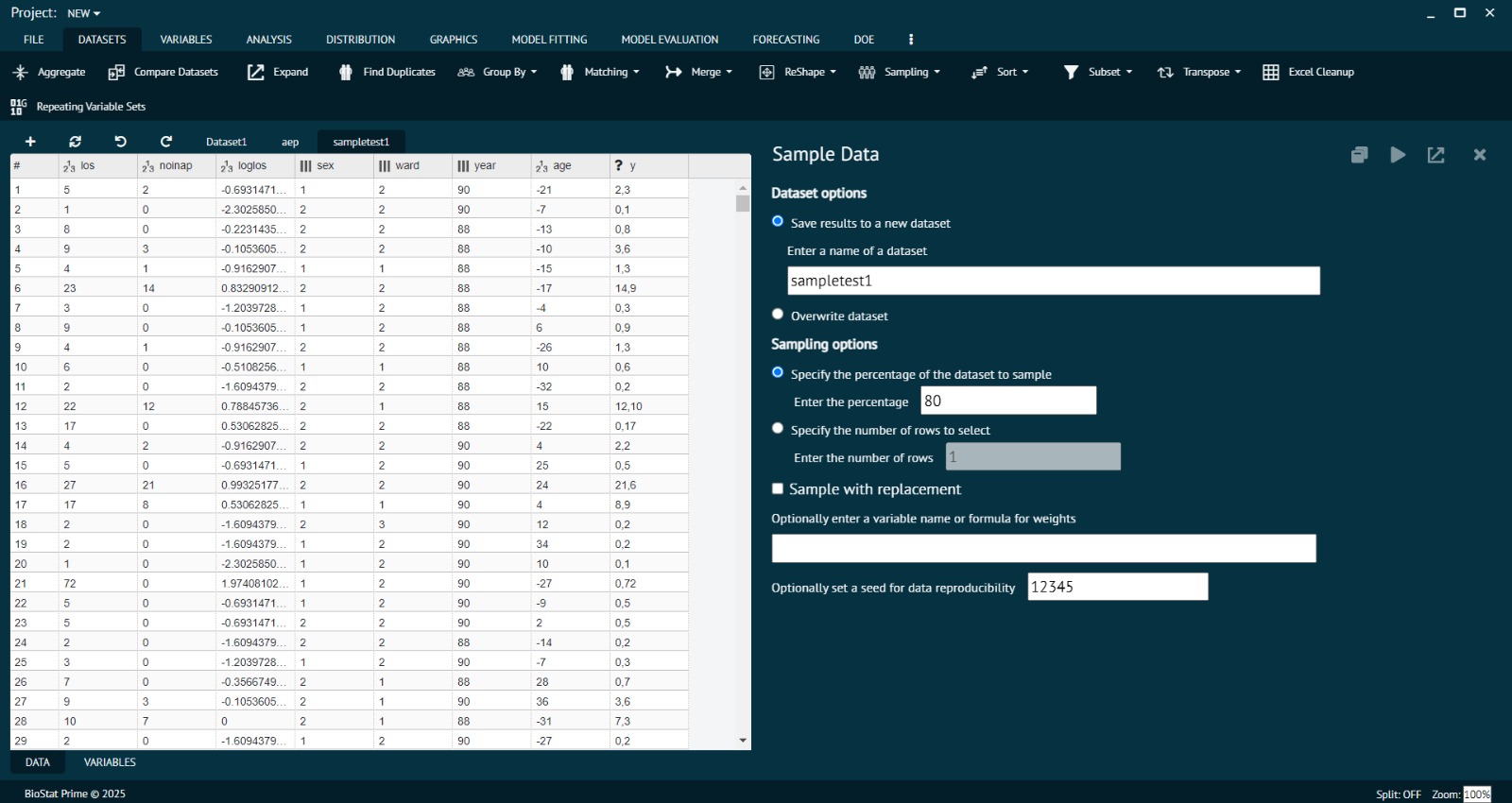
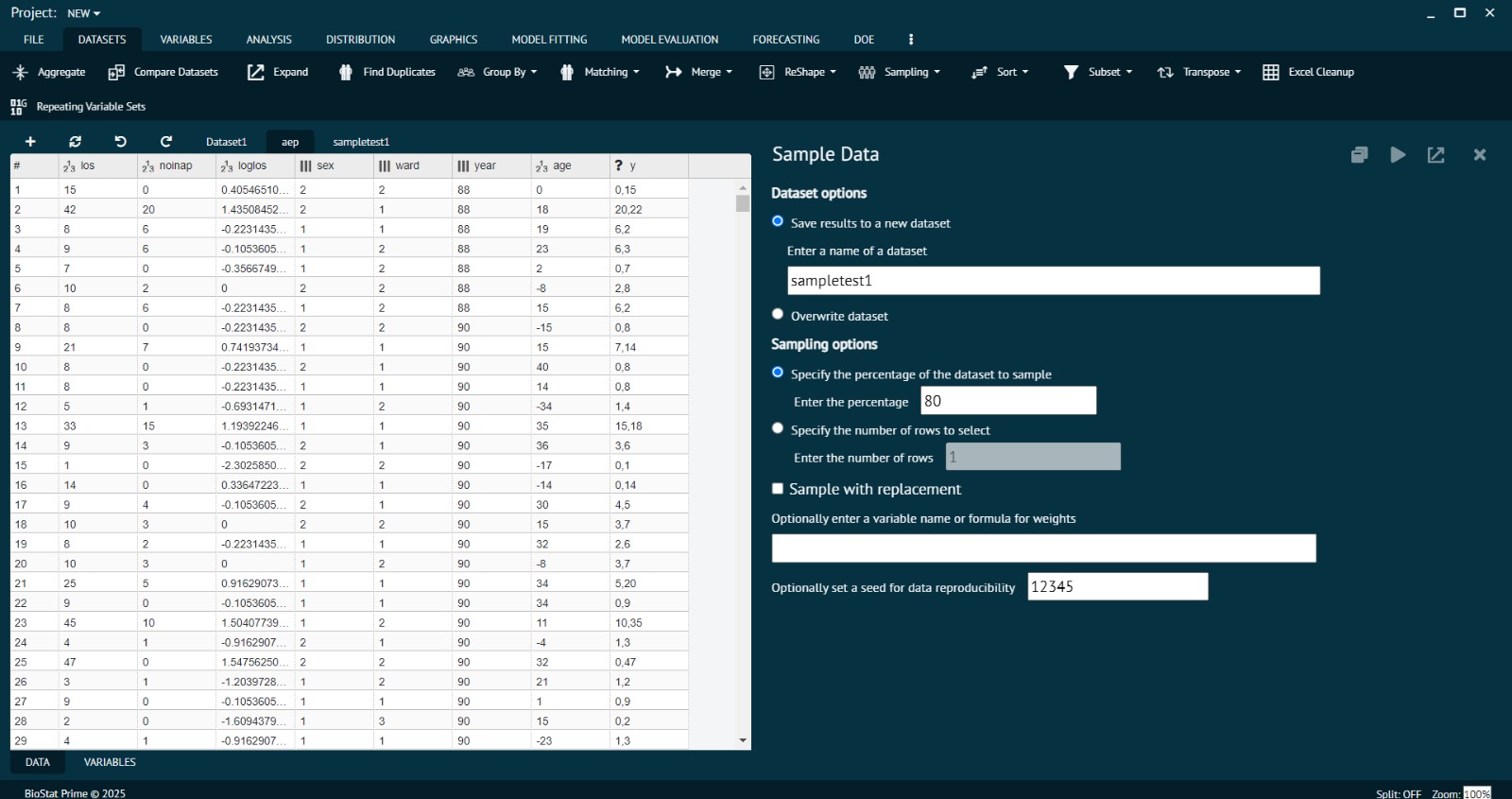
- Open the Dataset: Load the dataset you wish to sample in Biostat Prime’s data view window.
- Access the Sampling Tool: Navigate to the Data tab on the main toolbar, then select Sample Data from the dropdown options.
- Choose Sampling Method: Specify whether you want to select a fixed number of rows or a percentage of the dataset for sampling, and enter the desired number or percentage value.
- Set Replacement Option: Choose whether to sample with replacement (rows can be selected more than once) or without replacement (unique rows only).
- Execute Sampling: Click OK or Run to randomly select the subset of rows from the existing dataset.
- Save the Sampled Data: Choose to either save as a new dataset or overwrite the existing dataset based on your analysis needs, and provide a name if saving separately.
Types of Sampling Methods in Biostatistics
Sampling in biostatistics is generally divided into two major categories: Probability (Random) Sampling and Non-Probability Sampling.
Probability Sampling Methods
These methods reduce sampling bias and support statistical inference, allowing accurate estimation of population parameters such as confidence intervals and margins of error.
a) Simple Random Sampling
Each subject in the population has an equal chance of being selected. Example: Out of 500 participants, randomly select 60 by assigning each a number and drawing 60 numbers using a random generator.
b) Systematic Sampling
Samples are selected at regular intervals from a random starting point. Example: To select 100 samples from 1,000, calculate an interval of 10, pick a random start between 1 and 10, then select every 10th record.
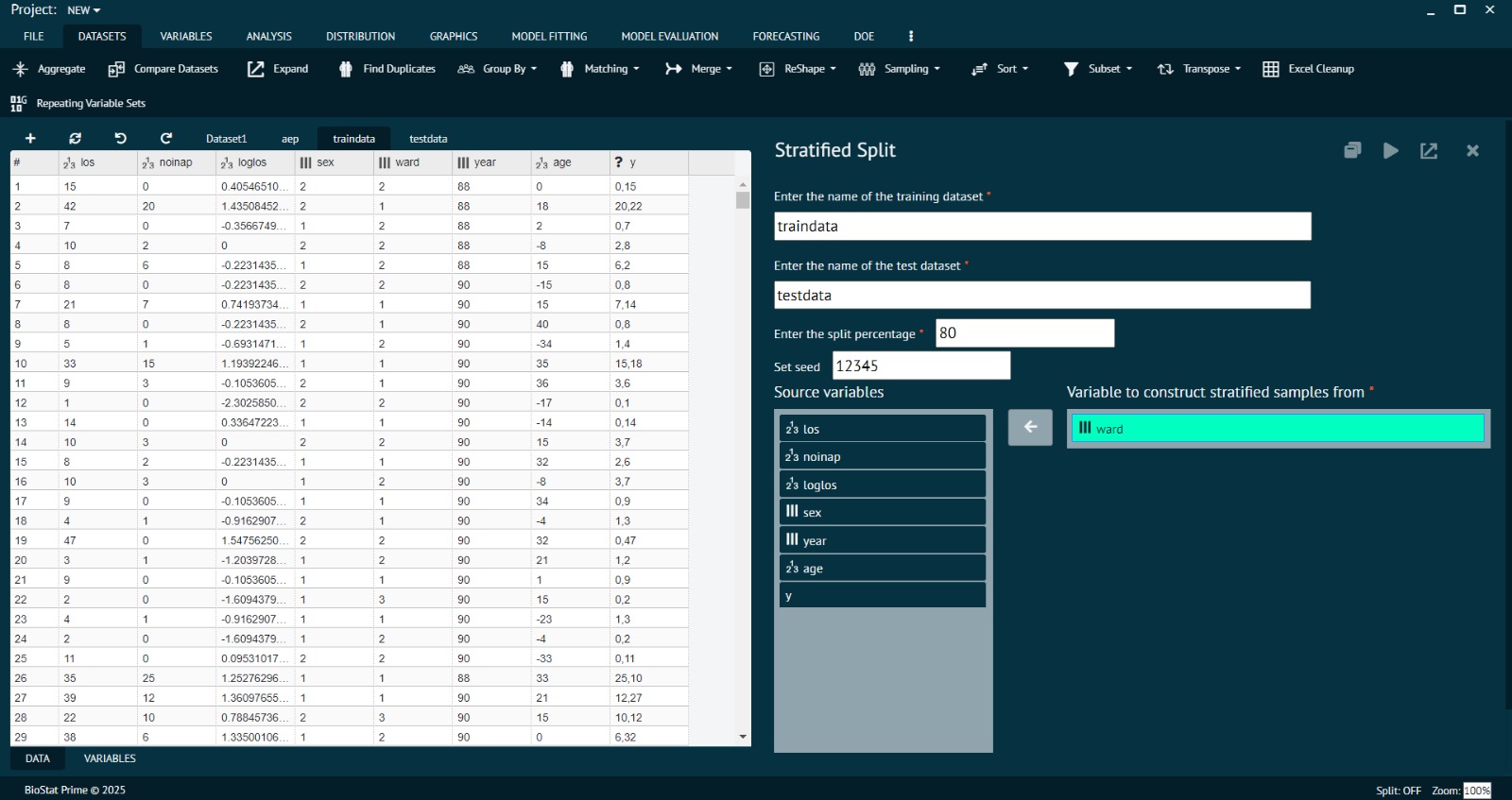
c) Stratified Sampling
The population is divided into subgroups (strata) that share common traits such as age, gender, or treatment type. Random samples are then taken from each subgroup, often in proportion to their size in the population. This ensures fair representation of all important subgroups
d) Cluster Sampling
The population is split into clusters, usually based on geographical or organizational units (e.g., clinics, cities). A few clusters are randomly selected, and all individuals within those clusters are included in the study. Example: From a list of 100 community health centers, randomly select 20 centers and collect data from all patients visiting those selected centers.
Each of these strategies offers unique advantages depending on study objectives, resources, and required precision.
Non-Probability Sampling Methods
These methods are often quicker and easier to apply but carry a higher risk of bias, making it difficult to generalize findings to the entire population.
a) Purposive (Judgmental) Sampling
Researchers deliberately select subjects most relevant to the study. Example: Choosing only cardiologists from a hospital to study cardiac-care practices.
b) Convenience Sampling
Samples are taken from individuals who are readily available or easy to reach, such as patients from a nearby clinic. Although practical, this technique may introduce bias and limit generalization. Example: Collecting survey responses only from participants attending a particular health awareness camp.
c) Quota Sampling
The researcher fixes quotas for certain groups (e.g., age or gender) and fills these quotas using convenience or purposive methods. This ensures inclusion of key subgroups while sacrificing some degree of randomness. Example: Ensuring that a sample includes 50 male and 50 female respondents by selecting the first qualifying participants available.
d) Snowball Sampling
This method of sample is suitable for studying rare or difficult-to-reach populations. The process begins with a few identified participants who then refer to others meeting the same selection criteria. Example: Starting with a few individuals diagnosed with a rare genetic disorder, who then refer other patients with the same condition to participate in the study.
Note:While non-probability sampling techniques are beneficial in exploratory or preliminary biostatistical research, results should be interpreted carefully, as they may not represent the entire population. Proper design, documentation, and methodological transparency enhance the credibility and reliability of findings.
Types of Sampling in Biostat Prime
Below we will be discussing different types of sampling methods implemented in Biostat Prime.
1. Up-Sampling
Definition: Up-sampling increases the number of data points in underrepresented groups.
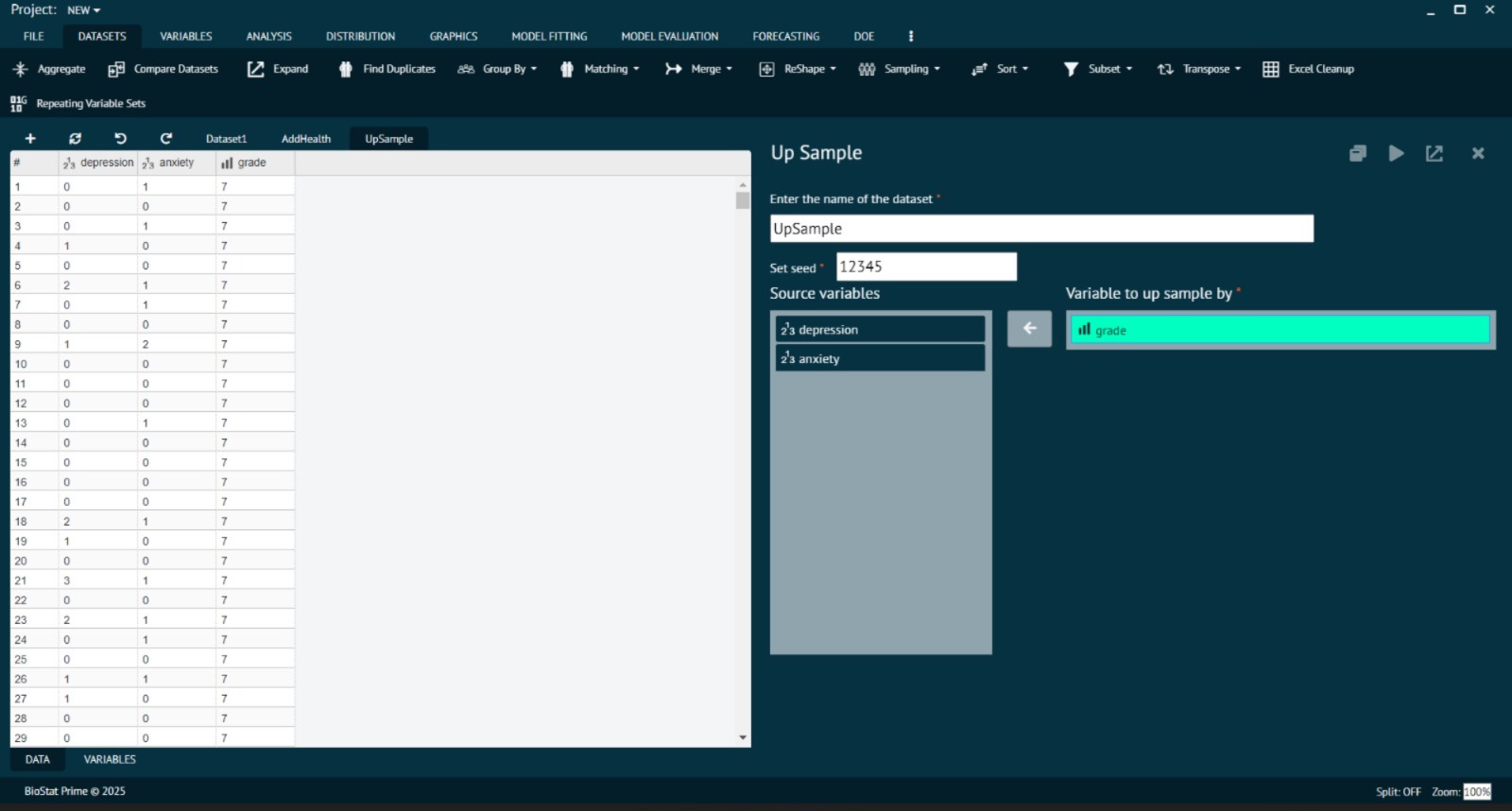
Example: Imagine a dataset of 1,000 patients where 800 are male and 200 are female. This imbalance (80% vs. 20%) can bias analysis. Up-sampling duplicates or synthetically generates female data so the dataset becomes balanced (800 vs. 800).
Advantages of Up-Sampling:
- Balances rare categories without losing valuable information.
- Prevents models from favoring majority classes.
- Improves sensitivity of statistical hypothesis testing.
Biostat Prime Features for Up-Sampling:
- Automated replication of minority classes.
- Resampling methods (bootstrapping) for robust modeling.
- Visual comparisons showing dataset balance before and after sampling.
2. Down-Sampling
Definition: Down-sampling reduces the number of data points in the majority group so both classes are balanced.
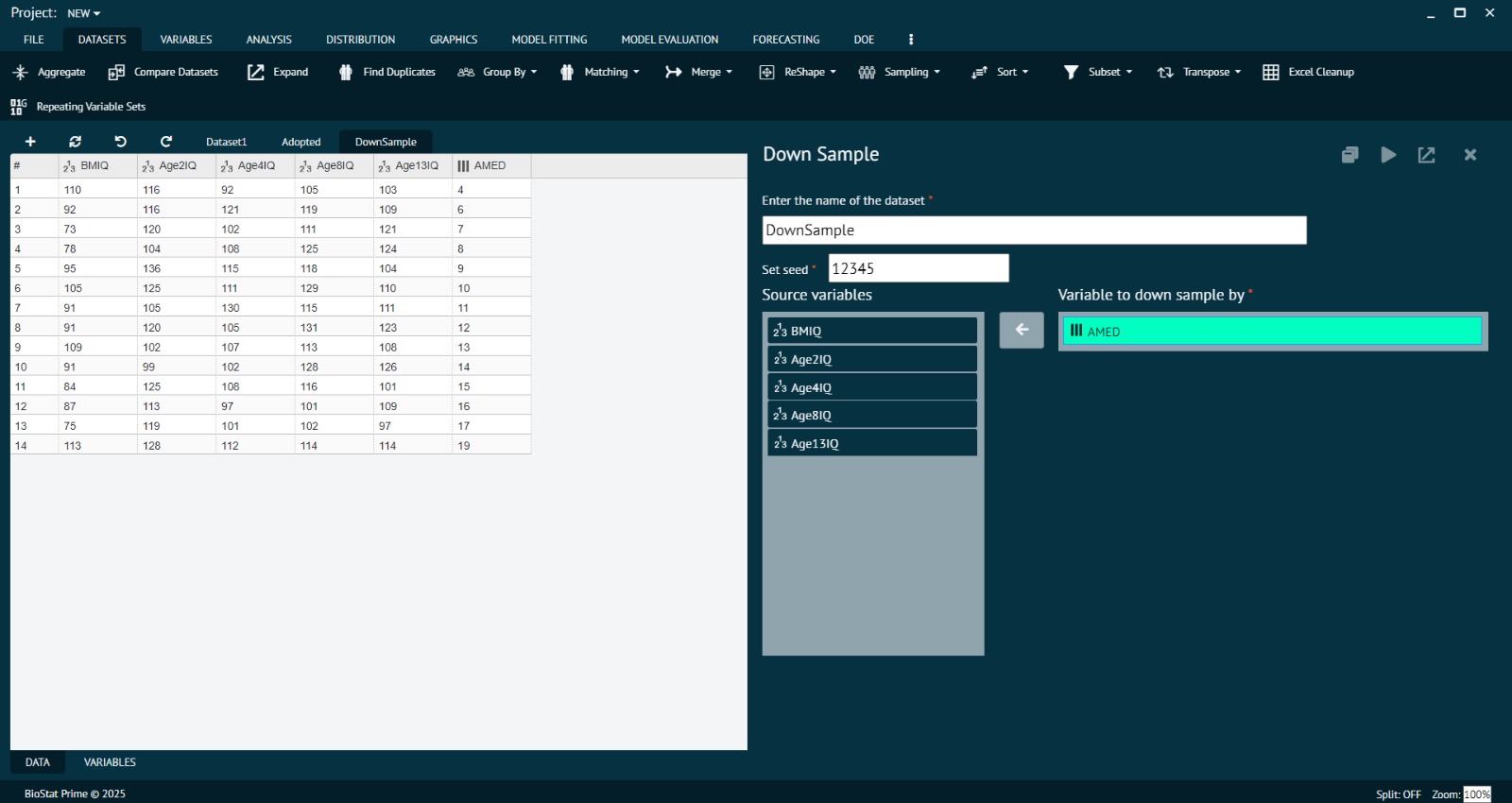
Example: Using the same dataset (800 male and 200 female patients), Biostat Prime down-samples by reducing the male sample size from 800 to 200, balancing both categories (200 vs. 200).
Advantages of Down-Sampling:
- Reduces computational load for large datasets.
- Minimizes redundancy in overrepresented classes.
- Avoids overfitting in unbalanced data analysis.
Biostat Prime Features for Down-Sampling:
- Controlled removal of data from majority groups.
- Tools that preserve representativeness after data reduction.
- Side-by-side visual graphs for pre- and post-sampling comparisons.
Case Study: Sampling in Clinical Research
A pharmaceutical company tested a new vaccine on 10,000 participants: 9,000 adults aged 40–60 and 1,000 adults aged 20–30. The imbalance caused bias, as the younger group was underrepresented.
- Solution in Biostat Prime:
- Researchers applied up-sampling to increase the 20–30 age group.
- They also tried down-sampling by reducing the 40–60 group for computational efficiency.
- Both methods helped create balanced statistical graphs and fairer comparison across age groups.
Result: Reduced bias, balanced statistical graphs, and reliable insights suitable for regulatory approval.
When to Use Up-Sampling vs. Down-Sampling
| Scenario | Recommended Method | Why |
|---|---|---|
| Rare disease dataset with few cases | Up-Sampling | Ensures minority cases are well represented |
| Large clinical trial (millions of rows) | Down-Sampling | Saves computation time while retaining balance |
| Academic study with limited subjects | Up-Sampling | Preserves all available data |
| Redundant majority class | Down-Sampling | Prevents overfitting and redundancy |
Many researchers combine both approaches for optimal results.
Best Practices for Sampling in Biostat Prime
- Always visualize before and after sampling. Use Biostat Prime’s charting tools to ensure balance
- Don’t over-replicate. Excessive up-sampling can create artificial bias if not controlled.
- Preserve randomness.In academic publications, clearly state whether you applied up-sampling, down-sampling, or both.
- Document your sampling process. In academic publications, clearly specify whether you used up-sampling, down-sampling, or both, along with parameters applied.
- Validate results with statistical tests. After sampling, run tests like chi-square, ANOVA, or regression models in Biostat Prime to ensure robustness.
Benefits of Sampling in Biostat Prime
- Improved Accuracy: Balanced groups reduce bias.
- Efficiency: Handles large datasets quickly
- Clarity: Produces cleaner, more interpretable graphs.
- Flexibility: Customizable sampling for research needs.
- Integration:Works seamlessly with other statistical tools in Biostat Prime.
FAQs
Sampling in Biostatistics – FAQs
Yes, Even large datasets can be skewed. For example, if 95% of patients are male, conclusions may not apply equally to females. Sampling corrects such imbalance.
Biostat Prime uses randomized selection algorithms to ensure fairness and prevent bias in up-sampling or down-sampling.
Yes, it can influence test sensitivity. Biostat Prime adjusts statistical outputs to account for resampling methods, providing reliable p-values and confidence intervals.
Unlike Excel, Biostat Prime integrates statistical rigor, advanced visualization, and automated controls. This ensures that sampling maintains scientific validity
Absolutely. Biostat Prime is optimized for large-scale datasets and provides efficient down-sampling to make analysis manageable without losing representativeness.
Yes. Biostat Prime allows sampling for both types, ensuring balance across categories as well as numerical ranges.
If applied excessively, yes. However, Biostat Prime uses controlled down-sampling, ensuring representative data is preserved while removing redundancy.
If the sample poorly represents the population, the study’s conclusions may be inaccurate or biased. This can lead to incorrect generalizations, misleading results, or poor decision-making in public health and scientific research.
Yes. In clinical research,it helps select participants who meet specific inclusion criteria. Proper sampling ensures that findings can be generalized to the broader patient population while maintaining ethical and logistical feasibility.
Conclusion
Sampling is fundamental to biostatistics , enabling researchers to draw valid inferences from representative subsets of data. While probability methods provide statistical rigor, non-probability techniques serve practical purposes when applied judiciously. Effective sampling through up sampling or down sampling is essential for achieving accuracy, balance, and efficiency in data analysis. With Biostat Prime’s advanced statistical and visualization capabilities, researchers can manage complex datasets with confidence and generate reliable, unbiased results across clinical, epidemiological, and pharmaceutical research domains.